
八卦协议:一个简单的服务发现方案
Updated:
Contents
八卦协议:一个简单的服务发现方案
背景
在微服务架构中,服务发现是一个常见需求。市面上有 Consul、Etcd、Nacos 等成熟方案,但对于小型集群(3~10 节点),这些方案显得有点”重”。
本文介绍一个基于八卦协议(Gossip Protocol)的轻量级服务发现方案:定时探测服务 status 接口,自动更新 Nginx upstream。
设计目标
- 简单、够用、清晰
- 无需引入额外组件
- 支持自动剔除故障节点
- 支持手动触发(紧急情况)
核心思想:无需时钟同步
分布式系统中,时钟同步是个老大难问题。本方案巧妙地绕过了它:
- 源头时间戳(src_ts):数据产生时的时间戳,用于判断数据新旧
- 本地收到时间(rcv_ts):本机收到数据的时间,用于判断是否过期
- 过期判断:
当前本地时间 - rcv_ts > TTL就认为过期
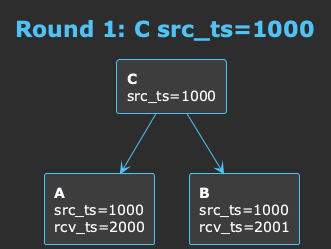
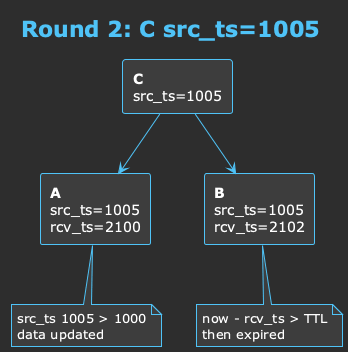
这样,即使各节点时钟不同步,也能正确判断数据新旧和过期。
流程设计
定时脚本(每5分钟)
↓
curl 各服务器的 /status 接口
↓
获取:版本号、时间戳、peers 列表
↓
更新本地缓存(cache.json)
↓
生成 upstream 配置(剔除过期节点)
↓
配置有变化 → nginx reload
status 接口设计
每个服务提供一个 /status 接口:
{
"status": "ok",
"service": "sleep",
"version": "1.2.3",
"timestamp": 1770088942,
"peers": ["10.0.0.5"]
}
关键字段:
timestamp:源头时间戳peers:随机返回 1/3 的已知节点(八卦协议精髓)version:服务版本,便于追踪
为什么只传 1/3 的 peers?
这是八卦协议的精髓:
- 数据量小:每次传输的数据量恒定
- 多轮覆盖:几轮下来自然传播完整
- 持续通信:吊胃口,下次还得来问
这种”不完整传播”的设计,让节点间保持持续的通信,同时避免了广播风暴。
缓存文件设计
使用一个 JSON 文件存储所有状态:
{
"services": {
"api": {
"port": 8861,
"instances": {
"10.0.0.3": {"version": "1.2.3", "src_ts": 1000, "rcv_ts": 2000},
"10.0.0.5": {"version": "1.2.3", "src_ts": 1000, "rcv_ts": 2001}
}
}
},
"peers": {
"10.0.0.3": {"src_ts": 1000, "rcv_ts": 2000},
"10.0.0.5": {"src_ts": 1000, "rcv_ts": 2001}
}
}
同步脚本核心逻辑
#!/bin/bash
CACHE_FILE="/etc/gossip/cache.json"
UPSTREAM_DIR="/etc/nginx/upstream.d"
TTL=600
NOW=$(date +%s)
# 探测所有服务
probe_all() {
local PEERS=$(jq -r ".peers | keys[]" $CACHE_FILE | shuf)
for IP in $PEERS; do
RESP=$(curl -s --connect-timeout 2 "http://$IP:$PORT/status")
# 解析响应,更新缓存...
done
}
# 生成 upstream 配置
generate_all() {
# 只保留未过期的节点
jq -r ".services.\"$SERVICE\".instances | to_entries[] |
select(($NOW - .value.rcv_ts) < $TTL) | ..."
}
优化策略
1. 增量探测
全量探测在大集群时效率低。可以只探测”快过期”的节点:
# 只探测剩余时间 < TTL/3 的节点
remaining = TTL - (NOW - rcv_ts)
if remaining < TTL/3:
probe(node)
2. 推模式
拉模式本质是轮询。对于大集群(>10 节点),可以加入推模式:
服务启动/停止 → 推给几个邻居 → 邻居再推给它的邻居 → 八卦扩散
实际效果
在我们的 3 节点集群中部署后:
$ /etc/gossip/sync-upstream.sh
[2026-02-03 19:27:01] ===== 开始同步 =====
[2026-02-03 19:27:01] 探测 api 10.0.0.2:8861 成功 version=20260203... ts=1770118021
[2026-02-03 19:27:01] upstream api 配置已变更
[2026-02-03 19:27:01] openresty 已重载
[2026-02-03 19:27:01] ===== 同步完成 =====
优点总结
| 特点 | 说明 |
|---|---|
| 简单 | 一个 Shell 脚本 + cron,无需额外组件 |
| 自愈 | 服务挂了自动剔除,恢复后自动加回 |
| 零侵入 | 只需服务提供 /status 接口 |
| 可扩展 | 小集群用拉模式,大集群加推模式 |
总结
对于小型集群,不一定需要重量级的服务发现组件。一个简单的八卦协议实现,配合 Nginx upstream 动态更新,就能满足大部分场景。
核心理念:简单、够用、清晰。