
无重复字符的最长子串
Updated:
无重复字符的最长子串
给定一个字符串,请你找出其中不含有重复字符的最长子串的长度。
- 示例 1:
输入: "abcabcbb" 输出: 3 解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。 - 示例 2:
输入: "bbbbb" 输出: 1 解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。 - 示例 3:
请注意,你的答案必须是 子串 的长度,”pwke” 是一个子序列,不是子串。输入: "pwwkew" 输出: 3 解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/longest-substring-without-repeating-characters
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
思路:
- 字符串从左往右遍历
i=0,第0个字符为新的开始索引index; - 将字符存入哈希表
map,value为该字符所在的索引i; - 继续遍历
i++;判断当前字符chars[i]是否在map中出现过:map不包含当前字符:- 将当前字符和索引
i存入map; - 因为有新的字符加入,所以这次的长度
length+1; - 对比最大值
result与length,取两者中的较大者;
- 将当前字符和索引
map包含当前字符,分两种情况:- 之前的旧的字符,落在了开始索引之后(或相等):
- 此时
length是不变的,比如:[pwe]w和p[wew]的长度都是3; - 但是因为遇到了重复字符,所以需要把
index更新为旧的字符所在的索引+1;
- 此时
- 之前的旧的字符,落在了开始索引之前:
- 因为之前的旧的字符超出了
index,相当于超出了统计范围,所以不再统计; - 将该字符的索引更新为新的索引;
- 因为之前的旧的字符超出了
- 之前的旧的字符,落在了开始索引之后(或相等):
- 遍历结束,
result为最终结果。
时间复杂度:
不考虑map的时间复杂度,只需要一次遍历,所以时间复杂度是O(N),N为字符串长度。
图解:
- 字符串从左往右遍历
i=0,第0个字符为新的开始索引index=0:
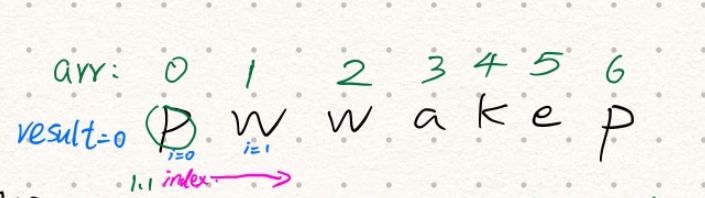
- 将字符存入哈希表
map,value为该字符所在的索引i;
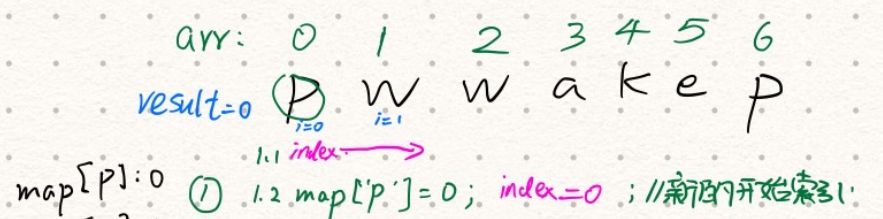
- 继续遍历
i++;判断当前字符chars[i]是否在map中出现过:map不包含当前字符:- 将当前字符和索引
i存入map; - 因为有新的字符加入,所以这次的长度
length+1; - 对比最大值
result与length,取两者中的较大者;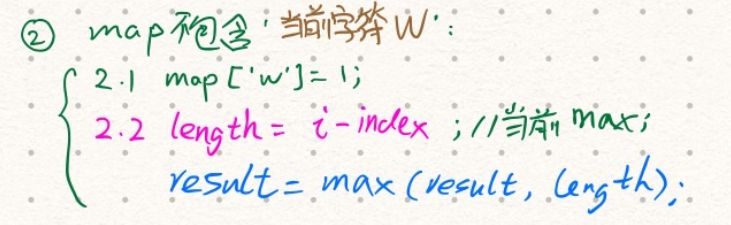
- 将当前字符和索引
map包含当前字符,分两种情况:- 之前的旧的字符,落在了开始索引之后(或相等):
- 此时
length是不变的,比如:[pwe]w和p[wew]的长度都是3; - 但是因为遇到了重复字符,所以需要把
index更新为旧的字符所在的索引+1;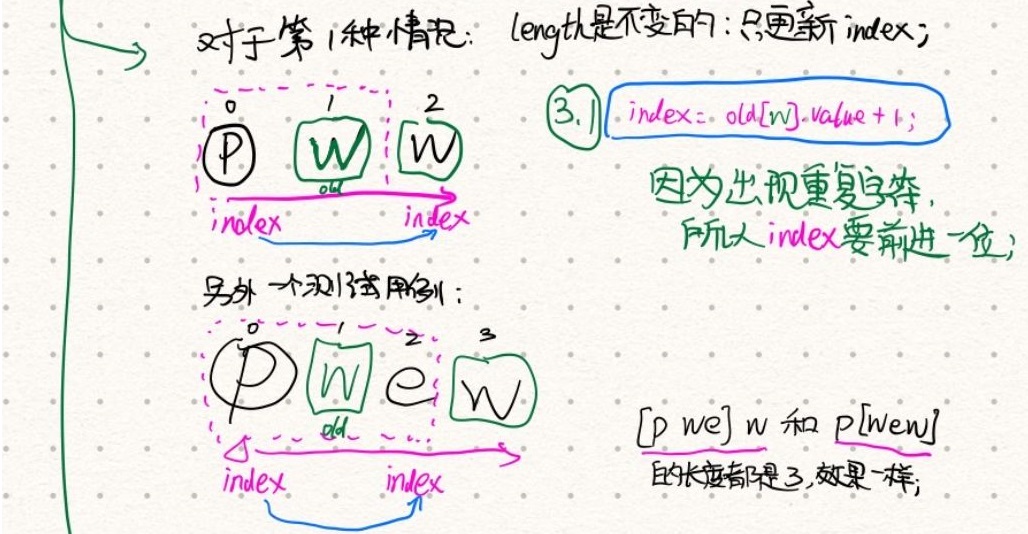
- 此时
- 之前的旧的字符,落在了开始索引之前:
- 因为之前的旧的字符超出了
index,相当于超出了统计范围,所以不再统计; - 将该字符的索引更新为新的索引;
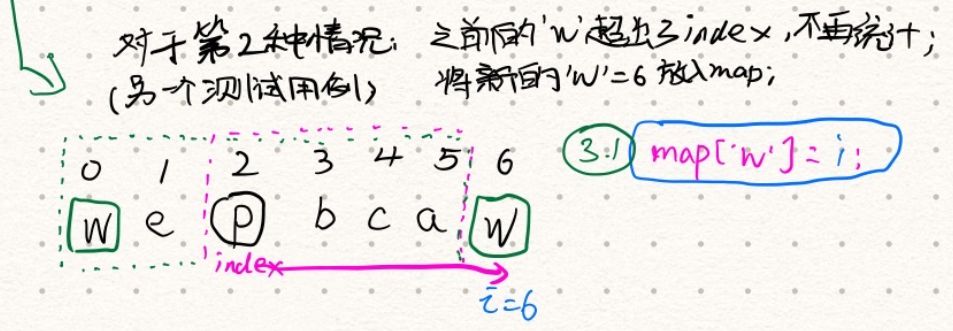
- 因为之前的旧的字符超出了
- 之前的旧的字符,落在了开始索引之后(或相等):
- 遍历结束,
result为最终结果。
示例代码:
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class SubString {
public static void main(String args[]) {
List<String> strings = Arrays.asList(new String[]{
"dvdf",
"aab",
"pwwkewwwskep",
"pwwwkew",
"pwwakepw",
"pww",
"bbbbbb",
"abcabcbb",
"ckilbkd"
});
strings.forEach(s ->
new Thread(() -> {
int m = lengthOfLongestSubstring(s);
System.out.println(s + " max: " + m);
}).start()
);
// dvdf max: 3
// pwwakepw max: 5
// pww max: 2
// pwwwkew max: 3
// bbbbbb max: 1
// aab max: 2
// pwwkewwwskep max: 5
// abcabcbb max: 3
// ckilbkd max: 5
}
public static int lengthOfLongestSubstring(String s) {
int index = 0; //新的开始索引;
int result = 0; //最终结果;
Map map = new HashMap<Character, Integer>();
char[] chars = s.toCharArray();
for (int i = 0; i < chars.length; i++) {
char current = chars[i];
if (map.containsKey(current)) {
int old = (int) map.get(current); //该字符旧的索引;
if (old >= index) { //如果旧值落在了之后:
index = old + 1; //将index前进一位,开始新的计数;
map.put(current, i); //更新一下索引;
} else { //如果旧值落在了之前:
map.put(current, i); //更新一下索引;
int length = i + 1 - index; //当前最大的长度;
result = Math.max(result, length); //当前最大的长度与之前的对比,取最大值;
}
} else {
map.put(current, i); //将当前字符和索引存入map;
int length = i + 1 - index; //当前最大的长度;
result = Math.max(result, length); //当前最大的长度与之前的对比,取最大值;
}
}
return result;
}
}
示例代码优化:
去掉if-else里面重复的判断逻辑。